on
Implementation of Transformer using PyTorch (detailed explanations )
Implementation of Transformer using PyTorch(detailed explanations).
Implementation of Transformer using PyTorch (detailed explanations)
The Transformer
The transformer is a neural network architecture that is widely used in NLP and CV. There are a lot of good blogs about it but most of them use a lot of PyTorch functions and common python packages and they assume that you have known about this knowledge so it is usually hard for the novice to fully understand these blogs. Instead, This blog will introduce how to code your Transformer from scratch, and I’ll also introduce the PyTorch functions and python packages which are an essential part of coding Transformer.The code of this blog can be found at https://github.com/Say-Hello2y/transformer

Just like other encoder-decoder architecture ,the encoder maps an input sequence of symbol representations \((x_1, ..., x_n)\) to a sequence of continuous representations \(\mathbf{z} = (z_1, ..., z_n)\) . Given \(\mathbf{z}\) , the decoder then generates an output sequence \((y_1,...,y_m)\) of symbols one element at a time. At each step the model is auto-regressive , consuming the previously generated symbols as additional input when generating the next.
As shown in the figure above, the Transformer is composed of N \(\times\) encoder-decoder blocks. Assumed the input sequences are English sentences and output is German sentences which means we use Transformer for machine translation. In this blog, I’ll introduce how to code Transformer through the order of the data process.
Now, let’s recall the process of training our model, firstly we get the training dataset (src, trg), which means the input English sentence (src) and corresponding German translation (trg) and we often need to preprocess it, then we input the processed data to our model, to be precise, the src data is sent to the encoder, and trg data is sent to the decoder where we use masked attention to keep the auto-regressive property, select loss function and use SGD to optimize our model to get ideal parameters to minimize the loss function.
Data preprocess
In the training loop, we need to preprocess our source data and convert it to batch_size
\(\times\)
sentence_length tensor, each row in the input tensor stands for a sentence, each element in the row stands for a word that is expressed by a token, and we often pad the sentence to a fixed length for better training our model.In practice, we also add an init_token
Torchtext
The torchtext package consists of data processing utilities and popular datasets for natural language.In this blog ,we use torchtext==0.6.0,and mainly use field & BucketIterator in torchtext.data.
torchtext.data.Field
classtorchtext.data.Field(sequential=True, use_vocab=True, init_token=None, eos_token=None, fix_length=None, dtype=torch.int64, preprocessing=None, postprocessing=None, lower=False, tokenize=None, tokenizer_language='en', include_lengths=False, batch_first=False, pad_token='<pad>', unk_token='<unk>', pad_first=False, truncate_first=False, stop_words=None, is_target=False)
Defines a datatype together with instructions for converting to Tensor.
Field class models common text processing datatypes that can be represented by tensors. It holds a Vocab object that defines the set of possible values for elements of the field and their corresponding numerical representations. The Field object also holds other parameters relating to how a datatype should be numericalized, such as a tokenization method and the kind of Tensor that should be produced.
If a Field is shared between two columns in a dataset (e.g., question and answer in a QA dataset), then they will have a shared vocabulary.
Variables:
- sequential – Whether the datatype represents sequential data. If False, no tokenization is applied. Default: True.
- use_vocab – Whether to use a Vocab object. If False, the data in this field should already be numerical. Default: True.
- init_token – A token that will be prepended to every example using this field, or None for no initial token. Default: None.
- eos_token – A token that will be appended to every example using this field, or None for no end-of-sentence token. Default: None.
- fix_length – A fixed length that all examples using this field will be padded to, or None for flexible sequence lengths. Default: None.
- dtype – The torch.dtype class that represents a batch of examples of this kind of data. Default: torch.long.
- preprocessing – The Pipeline that will be applied to examples using this field after tokenizing but before numericalizing. Many Datasets replace this attribute with a custom preprocessor. Default: None.
- postprocessing – A Pipeline that will be applied to examples using this field after numericalizing but before the numbers are turned into a Tensor. The pipeline function takes the batch as a list, and the field’s Vocab. Default: None.
- lower – Whether to lowercase the text in this field. Default: False.
- tokenize – The function used to tokenize strings using this field into sequential examples. If “spacy”, the SpaCy tokenizer is used. If a non-serializable function is passed as an argument, the field will not be able to be serialized. Default: string.split.
- tokenizer_language – The language of the tokenizer to be constructed. Various languages currently supported only in SpaCy.
- include_lengths – Whether to return a tuple of a padded minibatch and a list containing the lengths of each examples, or just a padded minibatch. Default: False.
- batch_first – Whether to produce tensors with the batch dimension first. Default: False.
- pad_token – The string token used as padding. Default: “
”. - unk_token – The string token used to represent OOV words. Default: “
”. - pad_first – Do the padding of the sequence at the beginning. Default: False.
- truncate_first – Do the truncating of the sequence at the beginning. Default: False
- stop_words – Tokens to discard during the preprocessing step. Default: None
- is_target – Whether this field is a target variable. Affects iteration over batches. Default: False
torchtext.data.BucketIterator
class torchtext.data.BucketIterator(dataset, batch_size, sort_key=None, device=None, batch_size_fn=None, train=True, repeat=False, shuffle=None, sort=None, sort_within_batch=None)
Defines an iterator that batches examples of similar lengths together.
For more detailed information, please see https://torchtextreadthedocs.io/en/latest/data.html#pipeline.
spacy
Spacy is an open-source software python library used in advanced natural language processing and machine learning. It will be used to build information extraction, natural language understanding systems, and to pre-process text for deep learning.
Here, it will be used for tokenization.
Preprocess code
from torchtext.data import Field, BucketIterator
from torchtext.datasets.translation import Multi30k
import spacy
from conf import *
class DataLoader:
source: Field = None
target: Field = None
def __init__(self, ext, tokenize_en, tokenize_de, init_token, eos_token):
self.ext = ext
self.tokenize_en = tokenize_en
self.tokenize_de = tokenize_de
self.init_token = init_token
self.eos_token = eos_token
print('dataset initializing start')
def make_dataset(self):
if self.ext == ('.de', '.en'):
self.source = Field(tokenize=self.tokenize_de, init_token=self.init_token, eos_token=self.eos_token,
lower=True, batch_first=True)
self.target = Field(tokenize=self.tokenize_en, init_token=self.init_token, eos_token=self.eos_token,
lower=True, batch_first=True)
elif self.ext == ('.en', '.de'):
self.source = Field(tokenize=self.tokenize_en, init_token=self.init_token, eos_token=self.eos_token,
lower=True, batch_first=True)
self.target = Field(tokenize=self.tokenize_de, init_token=self.init_token, eos_token=self.eos_token,
lower=True, batch_first=True)
train_data, valid_data, test_data = Multi30k.splits(exts=self.ext, fields=(self.source, self.target))
return train_data, valid_data, test_data
def build_vocab(self, train_data, min_freq):
self.source.build_vocab(train_data, min_freq=min_freq)
self.target.build_vocab(train_data, min_freq=min_freq)
def make_iter(self, train, validate, test, batch_size, device):
train_iterator, valid_iterator, test_iterator = BucketIterator.splits((train, validate, test),
batch_size=batch_size,
device=device)
print('dataset initializing done')
return train_iterator, valid_iterator, test_iterator
class Tokenizer:
def __init__(self):
self.spacy_de = spacy.load('de_core_news_sm')
self.spacy_en = spacy.load('en_core_web_sm')
def tokenize_de(self, text):
"""
Tokenizes German text from a string into a list of strings
"""
return [tok.text for tok in self.spacy_de.tokenizer(text)]
def tokenize_en(self, text):
"""
Tokenizes English text from a string into a list of strings
"""
return [tok.text for tok in self.spacy_en.tokenizer(text)]
tokenizer = Tokenizer()
loader = DataLoader(ext=('.en', '.de'),
tokenize_en=tokenizer.tokenize_en,
tokenize_de=tokenizer.tokenize_de,
init_token='<sos>',
eos_token='<eos>')
train, valid, test = loader.make_dataset()
loader.build_vocab(train_data=train, min_freq=2)
train_iter, valid_iter, test_iter = loader.make_iter(train, valid, test,
batch_size=batch_size,
device=device)
# pad 1 sos 2 eos 3
src_pad_idx = loader.source.vocab.stoi['<pad>']
# stoi = string to index ,we convert vocabulary to int index ,this function
# return the int index of corresponding vocabulary
trg_pad_idx = loader.target.vocab.stoi['<pad>']
trg_sos_idx = loader.target.vocab.stoi['<sos>']
enc_voc_size = len(loader.source.vocab)
dec_voc_size = len(loader.target.vocab)
'''
print(train_iter)
print(src_pad_idx)
print(trg_sos_idx)
print(loader.target.vocab.stoi['<eos>'])
print(enc_voc_size)
print(dec_voc_size)
output:
1
2
3
5893
7853
'''
Input Embedding & Positional Embedding
In machine translation, we often map each word to a word vector instead of one hot encoding. In Transformer, we map each word to a vector of size \(d_{model}=512\) and add positional information to the word vector, Vasmari et al use these functions to create a constant of positional embedding:
\[\begin{align*} PE_{(pos,2i)} = sin(pos / 10000^{2i/d_{model}}) \\ PE_{(pos,2i+1)} = cos(pos / 10000^{2i/d_{model}}) \end{align*}\]As is shown above, we can easily realize positional embedding by an element-wise operator but if we want to realize Input Embedding we need the nn.Embedding.
nn.Embedding
nn.Embedding()
A simple lookup table that stores embeddings of a fixed dictionary and size.
Parameters:
num_embeddings (int) – size of the dictionary of embeddings
embedding_dim (int) – the size of each embedding vector
Input : batch_size * sentence_length
while every element in the row is an index(int, from 0 to voc_length-1) which stands for a vocabulary
nn.Embedding maps the input index to an embedding vector and works like a lookup table
this layer's weight is a tensor of size voc_length*dmodel, each index stands for a unique vocabulary
and have an embedding vector whose values equal Weight[index,:], so this layer is just like a lookup table
>>> # an Embedding module containing 10 tensors of size 3
>>> embedding = nn.Embedding(10, 3)
>>> # a batch of 2 samples of 4 indices each
>>> input = torch.LongTensor([[1,2,4,5],[4,3,2,9]])
>>> embedding(input)
tensor([[[ 0.5532, -1.0127, 1.3929],
[ 0.0723, -0.3750, -0.0773],
[-0.3842, -1.3079, -0.9690],
[-1.8088, -0.3024, -1.9127]],
[[-0.3842, -1.3079, -0.9690],
[ 0.2600, -0.3750, 0.8686],
[ 0.0723, -0.3750, -0.0773],
[ 0.4828, -0.8169, 0.7782]]], grad_fn=<EmbeddingBackward0>)
>>> embedding.weight
Parameter containing:
tensor([[-1.0889, -0.8173, -0.9053],
[ 0.5532, -1.0127, 1.3929],
[ 0.0723, -0.3750, -0.0773],
[ 0.2600, -0.3750, 0.8686],
[-0.3842, -1.3079, -0.9690],
[-1.8088, -0.3024, -1.9127],
[-1.2135, 0.1929, 0.8181],
[-0.2911, 0.4599, -2.4593],
[-0.9330, 0.5497, 1.2579],
[ 0.4828, -0.8169, 0.7782]], requires_grad=True)
For more detail,see https://pytorch.org/docs/stable/generated/torch.nn.Embedding.html
Input Embedding & Positional Embedding code
import torch
from torch import nn
class PostionalEncoding(nn.Module):
"""
compute sinusoid encoding.
"""
def __init__(self, d_model, max_len, device):
"""
constructor of sinusoid encoding class
:param d_model: dimension of model
:param max_len: max sequence length
:param device: hardware device setting
"""
super(PostionalEncoding, self).__init__()
# same size with input matrix (for adding with input matrix)
self.encoding = torch.zeros(max_len, d_model, device=device)
self.encoding.requires_grad = False # we don't need to compute gradient
pos = torch.arange(0, max_len, device=device)
pos = pos.float().unsqueeze(dim=1)
# 1D => 2D unsqueeze to represent word's position
_2i = torch.arange(0, d_model, step=2, device=device).float()
# 'i' means index of d_model (e.g. embedding size = 50, 'i' = [0,50])
# "step=2" means 'i' multiplied with two (same with 2 * i)
self.encoding[:, 0::2] = torch.sin(pos / (10000 ** (_2i / d_model)))
self.encoding[:, 1::2] = torch.cos(pos / (10000 ** (_2i / d_model)))
# compute positional encoding to consider positional information of words
def forward(self, x):
# self.encoding
# [max_len = 512, d_model = 512]
batch_size, seq_len = x.size()
# [batch_size = 128, seq_len = 30]
return self.encoding[:seq_len, :]
# [seq_len = 30, d_model = 512]
# it will add with tok_emb : [128, 30, 512]
from torch import nn
class TokenEmbedding(nn.Embedding):
"""
Token Embedding using torch.nn
they will dense representation of word using weighted matrix
"""
def __init__(self, vocab_size, d_model):
"""
class for token embedding that included positional information
:param vocab_size: size of vocabulary
:param d_model: dimensions of model
"""
super(TokenEmbedding, self).__init__(vocab_size, d_model, padding_idx=1)
class TransformerEmbedding(nn.Module):
"""
token embedding + positional encoding (sinusoid)
positional encoding can give positional information to network
"""
def __init__(self, vocab_size, d_model, max_len, drop_prob, device):
"""
class for word embedding that included positional information
:param vocab_size: size of vocabulary
:param d_model: dimensions of model
"""
super(TransformerEmbedding, self).__init__()
self.tok_emb = TokenEmbedding(vocab_size, d_model)
self.pos_emb = PostionalEncoding(d_model, max_len, device)
self.drop_out = nn.Dropout(p=drop_prob)
def forward(self, x):
tok_emb = self.tok_emb(x)
pos_emb = self.pos_emb(x)
return self.drop_out(tok_emb + pos_emb)
Multi-Head Attention(Masked opt)
Scaled Dot-Product Attention
Attention in machine learning means we use an attention function to map a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key. In ‘Attention is all you need ‘, the input consists of queries and keys of dimension \(d_k\) , and values of dimension \(d_v\) . They compute the dot products of the query with all keys, divide each by \(\sqrt{d_k}\) , and apply a softmax function to obtain the weights on the values.
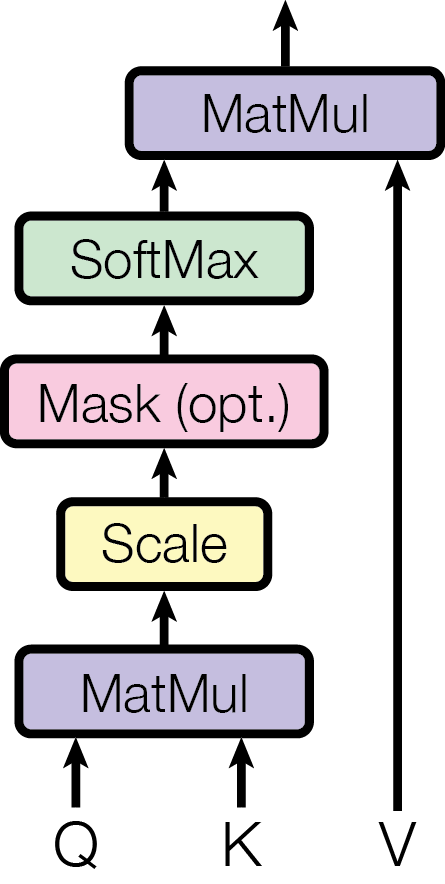
Here is the code of Scaled Dot-Product Attention.
import math
from torch import nn
class ScaleDotProductAttention(nn.Module):
"""
compute scale dot product attention
Query : given sentence that we focused on (decoder)
Key : every sentence to check relationship with Qeury(encoder)
Value : every sentence same with Key (encoder)
"""
def __init__(self):
super(ScaleDotProductAttention, self).__init__()
self.softmax = nn.Softmax(dim=-1)
def forward(self, q, k, v, mask=None, e=1e12):
# input is 4 dimension tensor
# [batch_size, head, length, d_tensor]
batch_size, head, length, d_tensor = k.size()
# 1. dot product Query with Key^T to compute similarity
k_t = k.transpose(2, 3) # transpose
score = (q @ k_t) / math.sqrt(d_tensor) # scaled dot product
# 2. apply masking (opt)
if mask is not None:
score = score.masked_fill(mask == 0, -e)
# 3. pass them softmax to make [0, 1] range
score = self.softmax(score)
# 4. multiply with Value
v = score @ v
return v, score
There is an important function torch.masked_fill()
Tensor.masked_fill_(mask, value)
Fills elements of self tensor with value where mask is True. The shape of mask must be broadcastable with the shape of the underlying tensor.
Parameters
- mask (BoolTensor) – the boolean mask
- value (float) – the value to fill in with
import torch
a=torch.tensor([[[5,5,5,5], [6,6,6,6], [7,7,7,7]], [[1,1,1,1],[2,2,2,2],[3,3,3,3]]])
print(a)
print(a.size())
print("#############################################3")
mask = torch.ByteTensor([[[1],[1],[0]],[[0],[1],[1]]])
print(mask.size())
b = a.masked_fill(mask, value=torch.tensor(-1e9))
print(b)
print(b.size())
'''
output:
tensor([[[5, 5, 5, 5],
[6, 6, 6, 6],
[7, 7, 7, 7]],
[[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3]]])
torch.Size([2, 3, 4])
#############################################3
torch.Size([2, 3, 1])
b = a.masked_fill(mask, value=torch.tensor(-1e9))
tensor([[[-1000000000, -1000000000, -1000000000, -1000000000],
[-1000000000, -1000000000, -1000000000, -1000000000],
[ 7, 7, 7, 7]],
[[ 1, 1, 1, 1],
[-1000000000, -1000000000, -1000000000, -1000000000],
[-1000000000, -1000000000, -1000000000, -1000000000]]])
torch.Size([2, 3, 4])
'''
Multi-Head Attention
In Transformer, to attend to information from different representation subspaces at different positions, we use Multi-Head Attention, which instead of performing a single attention function with \(d_{model}\)-dimensional keys, values and queries, we linearly project the queries, keys and values \(h\) times with different, learned linear projections to \(d_k\) , \(d_k\) and \(d_v\) dimensions, respectively. On each of these projected versions of queries, keys, and values we then perform the attention function in parallel, yielding \(d_v\) -dimensional output values. These are concatenated and once again projected, resulting in the final values, as depicted in the Figure below.
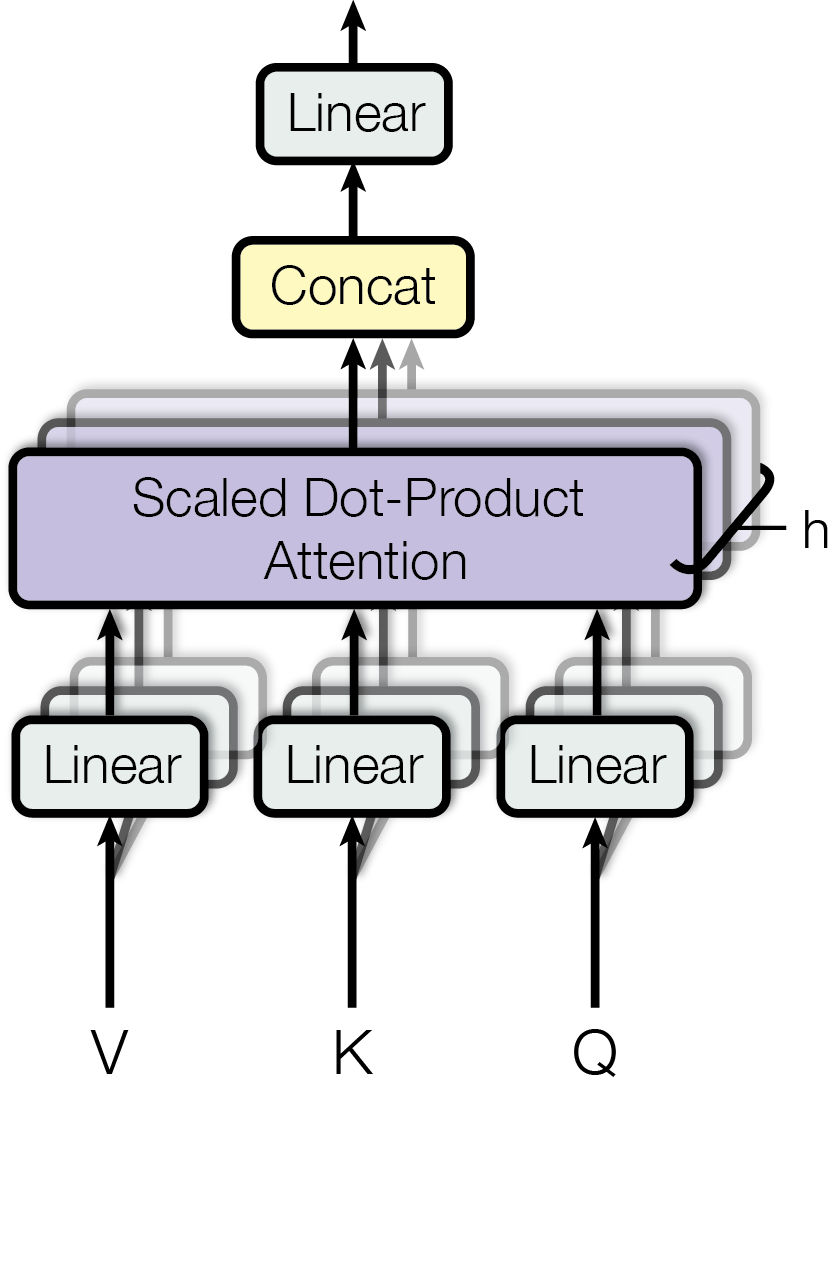
Where the projections are parameter matrices \(W^Q_i \in \mathbb{R}^{d_{model} \times d_k}\) , \(W^K_i \in \mathbb{R}^{d_{model} \times d_k}\) , \(W^V_i \in \mathbb{R}^{d_{model} \times d_v}\) and \(W^O \in \mathbb{R}^{hd_v \times d_{model}}\).
In this work we employ \(h=8\) parallel attention layers, or heads. For each of these we use \(d_k=d_v=d_{model}/h=64\). Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.
Here is the code of Multi-Head Attention:
import math
from torch import nn
class ScaleDotProductAttention(nn.Module):
"""
compute scale dot product attention
Query : given sentence that we focused on (decoder)
Key : every sentence to check relationship with Qeury(encoder)
Value : every sentence same with Key (encoder)
"""
def __init__(self):
super(ScaleDotProductAttention, self).__init__()
self.softmax = nn.Softmax(dim=-1)
def forward(self, q, k, v, mask=None, e=1e12):
# input is 4 dimension tensor
# [batch_size, head, length, d_tensor]
batch_size, head, length, d_tensor = k.size()
# 1. dot product Query with Key^T to compute similarity
k_t = k.transpose(2, 3) # transpose
score = (q @ k_t) / math.sqrt(d_tensor) # scaled dot product
# 2. apply masking (opt)
if mask is not None:
score = score.masked_fill(mask == 0, -e)
# 3. pass them softmax to make [0, 1] range
score = self.softmax(score)
# 4. multiply with Value
v = score @ v
return v, score
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_head):
super(MultiHeadAttention, self).__init__()
self.n_head = n_head
self.attention = ScaleDotProductAttention()
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_concat = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
# 1. dot product with weight matrices
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v)
# 2. split tensor by number of heads
q, k, v = self.split(q), self.split(k), self.split(v)
# 3. do scale dot product to compute similarity
out, attention = self.attention(q, k, v, mask=mask)
# 4. concat and pass to linear layer
out = self.concat(out)
out = self.w_concat(out)
# 5. visualize attention map
# TODO : we should implement visualization
return out
def split(self, tensor):
"""
split tensor by number of head
:param tensor: [batch_size, length, d_model]
:return: [batch_size, head, length, d_tensor]
"""
batch_size, length, d_model = tensor.size()
d_tensor = d_model // self.n_head
tensor = tensor.view(batch_size, length, self.n_head, d_tensor).transpose(1, 2)
# it is similar with group convolution (split by number of heads)
return tensor
def concat(self, tensor):
"""
inverse function of self.split(tensor : torch.Tensor)
:param tensor: [batch_size, head, length, d_tensor]
:return: [batch_size, length, d_model]
"""
batch_size, head, length, d_tensor = tensor.size()
d_model = head * d_tensor
tensor = tensor.transpose(1, 2).contiguous().view(batch_size, length, d_model)
return tensor
Masked
There are three types of attention in the Transformer, this is encoder self-attention, decoder self-attention, and encoder-decoder attention where the query from the decoder and key, value from the encoder hidden layer output. As is shown above, we pad the src data and trg data so we must prevent this padding affect our training, this question can be solved by make_pad_mask.To keep the auto-regressive property, we use the masked-attention, which prevents the query peek the next key and only using all the previous keys, this question can be solved by make_no_peak_mask.
we can understand the make_no_peak_mask through this formula:
\[\begin{equation} \mathrm{Attention}_{masked}(Q, K, V) = \mathrm{softmax}(\frac{QK^T+M}{\sqrt{d_k}})V \end{equation}\]where
\[\begin{equation} M=[m_{ij}],m_{ij}==\left\{ \begin{aligned} 0 & , & i \geq j \\ -\infty & , & other \end{aligned} \right. \end{equation}\] \[Q_{sentence\_length,d_{k}}=\begin{bmatrix} q_1^T \\ \vdots \\ q_n^T\end{bmatrix} \quad K_{sentence\_length,d_{k}}=\begin{bmatrix} k_1^T \\ \vdots \\ k_n^T\end{bmatrix}\]So if we want to mask future position, we only need to create a lower triangular matrix in which upper triangular elements are zero, then through the torch.masked_fill() we can let upper triangular elements to a very small negative number, eg -1e12.
In the encoder self-attention, we use the make_pad_mask to eliminate the effect of padding, in the decoder self-attention we use both make_pad_mask and make_no_peak_mask to eliminate the effect of padding and keep the auto-regressive property, in the encoder-decoder we only use make_pad_mask the eliminate the effect of padding.
Here is the code of make_pad_mask and make_no_peak_mask :
def make_pad_mask(self, q, k):
#in nlp we often pad the sentence to fixed_len, so we should mask the padding when training
len_q, len_k = q.size(1), k.size(1)
# batch_size x 1 x 1 x len_k
k = k.ne(self.src_pad_idx).unsqueeze(1).unsqueeze(2)
# batch_size x 1 x len_q x len_k
k = k.repeat(1, 1, len_q, 1)
# batch_size x 1 x len_q x 1
q = q.ne(self.src_pad_idx).unsqueeze(1).unsqueeze(3)
# batch_size x 1 x len_q x len_k
q = q.repeat(1, 1, 1, len_k)
mask = k & q
return mask
def make_no_peak_mask(self, q, k):
# prevent 'peek ahead'
len_q, len_k = q.size(1), k.size(1)
# len_q x len_k
mask = torch.tril(torch.ones(len_q, len_k)).type(torch.BoolTensor).to(self.device)
return mask
Residual Connection & Layer Norm
In each sublayer, The Transformer also employs a residual connection to facilitate constructing a deeper network, followed by layer normalization to facilitate training.That is, the output of each sub-layer is \(\mathrm{LayerNorm}(x + \mathrm{Sublayer}(x))\) , where \(\mathrm{Sublayer}(x)\) is the function implemented by the sub-layer itself which could be Attention Layer or point-wise feedforward network. To facilitate these residual connections, all sub-layers in the Transformer, as well as the embedding layers, produce outputs of dimension \(d_{model}=512\).
As for layer normalization ,we can compare it with batch normalization .
Batch Normalization aims to reduce internal covariate shift, and in doing so aims to accelerate the training of deep neural nets. It accomplishes this via a normalization step that fixes the means and variances of layer inputs. Batch Normalization also has a beneficial effect on the gradient flow through the network, by reducing the dependence of gradients on the scale of the parameters or of their initial values. This allows for use of much higher learning rates without the risk of divergence. Furthermore, batch normalization regularizes the model and reduces the need for Dropout.
We apply a batch normalization layer as follows for a minibatch \(\mathcal{B}\)
\[\mu_{\mathcal{B}} = \frac{1}{m}\sum^{m}_{i=1}x_{i}\] \[\sigma^{2}_{\mathcal{B}} = \frac{1}{m}\sum^{m}_{i=1}\left(x_{i}-\mu_{\mathcal{B}}\right)^{2}\] \[\hat{x}_{i} = \frac{x_{i} - \mu_{\mathcal{B}}}{\sqrt{\sigma^{2}_{\mathcal{B}}+\epsilon}}\] \[y_{i} = \gamma\hat{x}_{i} + \beta = \text{BN}_{\gamma, \beta}\left(x_{i}\right)\]Where \(\gamma\) and \(\beta\) are learnable parameters.But for batch normalization, when we evaluate our model, we input a test smaple but a test sample is hard to say it’s mean and variance, and if you think the mean of a test sample is itself and variance is zero, there will be another big question the \(\hat{x_i}=0\) according to the formula above. So when we use batch normalization, we need to store the means and variances of training batch data, which could introduce the dependencies to training data.

Unlike batch normalization, Layer Normalization directly estimates the normalization statistics from the summed inputs to the neurons within a hidden layer so the normalization does not introduce any new dependencies between training cases. It works well for RNNs and improves both the training time and the generalization performance of several existing RNN models. More recently, it has been used with Transformer models.
We compute the layer normalization statistics over all the hidden units in the same layer as follows:
\[\mu^{l} = \frac{1}{H}\sum^{H}_{i=1}a_{i}^{l}\] \[\sigma^{l} = \sqrt{\frac{1}{H}\sum^{H}_{i=1}\left(a_{i}^{l}-\mu^{l}\right)^{2}}\]where \(H\) denotes the number of hidden units in a layer. Under layer normalization, all the hidden units in a layer share the same normalization terms \(\mu\) and \(\theta\), but different training cases have different normalization terms. Unlike batch normalization, layer normalization does not impose any constraint on the size of the mini-batch and it can be used in the pure online regime with batch size 1. You can think layer normalization is aimed at each layer’s output instead of batch data itself.
Here is the code of layer normalization. As for the residual connection, it can be easily implemented through the nn. forward, so I don’t put an independent code on it.
import torch
from torch import nn
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-12):
super(LayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
self.eps = eps # eps is a little positive number which is used to prevent divided zero
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
# '-1' means last dimension.
out = (x - mean) / (std + self.eps)
out = self.gamma * out + self.beta
return out
Position-wise Feed-Forward Networks
Position-wise feed-forward networks is a simple MLP ,which is applied to each position separately and identically.This consists of two linear transformations with a ReLU activation in between. \(\begin{equation} \mathrm{FFN}(x)=\max(0, xW_1 + b_1) W_2 + b_2 \end{equation}\) Here is the code of positional-wise feed-forward networks.
from torch import nn
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, hidden, drop_prob=0.1):
super(PositionwiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, hidden)
self.linear2 = nn.Linear(hidden, d_model)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=drop_prob)
def forward(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.linear2(x)
return x
The Encoder & Decoder
The encoder & decoder is a set of the above sublayer, if you have understood the details above, you now understand the Transformer. The rest is simply putting all of it together. But there is another great detail in training, which will be shown in the training chapter.
Here is the code of encoder & decoder.
# encoder
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm1 = LayerNorm(d_model=d_model)
self.dropout1 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.norm2 = LayerNorm(d_model=d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
def forward(self, x, s_mask):
# 1. compute self attention
_x = x
x = self.attention(q=x, k=x, v=x, mask=s_mask)
x = self.dropout1(x)
# 2. add and norm
x = self.norm1(x + _x)
# 3. positionwise feed forward network
_x = x
x = self.ffn(x)
x = self.dropout2(x)
# 4. add and norm
x = self.norm2(x + _x)
return x
class Encoder(nn.Module):
def __init__(self, enc_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob, device):
super().__init__()
self.emb = TransformerEmbedding(d_model=d_model,
max_len=max_len,
vocab_size=enc_voc_size,
drop_prob=drop_prob,
device=device)
self.layers = nn.ModuleList([EncoderLayer(d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob)
for _ in range(n_layers)])
def forward(self, x, s_mask):
x = self.emb(x)
for layer in self.layers:
x = layer(x, s_mask)
return x
# decoder
class DecoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(DecoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm1 = LayerNorm(d_model=d_model)
self.dropout1 = nn.Dropout(p=drop_prob)
self.enc_dec_attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm2 = LayerNorm(d_model=d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.norm3 = LayerNorm(d_model=d_model)
self.dropout3 = nn.Dropout(p=drop_prob)
def forward(self, dec, enc, t_mask, s_mask):
# 1. compute self attention
_x = dec
x = self.self_attention(q=dec, k=dec, v=dec, mask=t_mask)
x = self.dropout1(x)
# 2. add and norm
x = self.norm1(x + _x)
if enc is not None:
# 3. compute encoder - decoder attention
_x = x
x = self.enc_dec_attention(q=x, k=enc, v=enc, mask=s_mask)
x = self.dropout2(x)
# 4. add and norm
x = self.norm2(x + _x)
# 5. positionwise feed forward network
_x = x
x = self.ffn(x)
x = self.dropout3(x)
# 6. add and norm
x = self.norm3(x + _x)
return x
class Decoder(nn.Module):
def __init__(self, dec_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob, device):
super().__init__()
self.emb = TransformerEmbedding(d_model=d_model,
drop_prob=drop_prob,
max_len=max_len,
vocab_size=dec_voc_size,
device=device)
self.layers = nn.ModuleList([DecoderLayer(d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob)
for _ in range(n_layers)])
self.linear = nn.Linear(d_model, dec_voc_size)
def forward(self, trg, enc_src, trg_mask, src_mask):
trg = self.emb(trg)
for layer in self.layers:
trg = layer(trg, enc_src, trg_mask, src_mask)
# pass to LM head
output = self.linear(trg)
return output
The Transformer(Code)
The Transformer is composed of a stack of \(N=6\) identical encoder-decoder blocks.
Here is the code of the Transformer.
class Transformer(nn.Module):
def __init__(self, src_pad_idx, trg_pad_idx, trg_sos_idx, enc_voc_size, dec_voc_size, d_model, n_head, max_len,
ffn_hidden, n_layers, drop_prob, device):
super().__init__()
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
self.trg_sos_idx = trg_sos_idx
self.device = device
self.encoder = Encoder(d_model=d_model,
n_head=n_head,
max_len=max_len,
ffn_hidden=ffn_hidden,
enc_voc_size=enc_voc_size,
drop_prob=drop_prob,
n_layers=n_layers,
device=device)
self.decoder = Decoder(d_model=d_model,
n_head=n_head,
max_len=max_len,
ffn_hidden=ffn_hidden,
dec_voc_size=dec_voc_size,
drop_prob=drop_prob,
n_layers=n_layers,
device=device)
def forward(self, src, trg):
src_mask = self.make_pad_mask(src, src) # use for encoder self-attention
src_trg_mask = self.make_pad_mask(trg, src) # use for encoder decoder attention
trg_mask = self.make_pad_mask(trg, trg) * \
self.make_no_peak_mask(trg, trg) # decoder self attention & no peek decoder self-attention
enc_src = self.encoder(src, src_mask)
output = self.decoder(trg, enc_src, trg_mask, src_trg_mask)
return output
def make_pad_mask(self, q, k):
#in nlp we often pad the sentence to max_len, so we should mask the padding when training
len_q, len_k = q.size(1), k.size(1)
# batch_size x 1 x 1 x len_k
k = k.ne(self.src_pad_idx).unsqueeze(1).unsqueeze(2)
# batch_size x 1 x len_q x len_k
k = k.repeat(1, 1, len_q, 1)
# batch_size x 1 x len_q x 1
q = q.ne(self.src_pad_idx).unsqueeze(1).unsqueeze(3)
# batch_size x 1 x len_q x len_k
q = q.repeat(1, 1, 1, len_k)
mask = k & q
return mask
def make_no_peak_mask(self, q, k):
# prevent 'peek ahead'
len_q, len_k = q.size(1), k.size(1)
# len_q x len_k
mask = torch.tril(torch.ones(len_q, len_k)).type(torch.BoolTensor).to(self.device)
return mask
Training
There is an important detail when we train the model because the model is auto-regressive, so we should delete the last token in each sentence for we predict the next token based on the previous tokens, it’s no need to keep the last token in the sentence. When calculating the loss function, we need to delete
the first token in each sentence, which is a special token
Here is the code of training.
model = Transformer(src_pad_idx=src_pad_idx,
trg_pad_idx=trg_pad_idx,
trg_sos_idx=trg_sos_idx,
d_model=d_model,
enc_voc_size=enc_voc_size,
dec_voc_size=dec_voc_size,
max_len=max_len,
ffn_hidden=ffn_hidden,
n_head=n_heads,
n_layers=n_layers,
drop_prob=drop_prob,
device=device).to(device)
print(f'The model has {count_parameters(model):,} trainable parameters')
model.apply(initialize_weights)
optimizer = Adam(params=model.parameters(),
lr=init_lr,
weight_decay=weight_decay,
eps=adam_eps)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer,
verbose=True,
factor=factor,
patience=patience)
criterion = nn.CrossEntropyLoss(ignore_index=src_pad_idx)
def train(model, iterator, optimizer, criterion, clip):
model.train()
epoch_loss = 0
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
# print(trg)
# print(src.size())
# print(trg.size())
optimizer.zero_grad()
# the trg sentence we input has all words except
# the last, as it is using each word to predict the next
output = model(src, trg[:, :-1]) # multi sentence parallel training
# print(trg[:,:-1])
# print(output.size())
output_reshape = output.contiguous().view(-1, output.shape[-1]) # output,shape[-1]: voc length
# print(output_reshape.size())
trg = trg[:, 1:].contiguous().view(-1)
# print(trg.size())
loss = criterion(output_reshape, trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
epoch_loss += loss.item()
print('step :', round((i / len(iterator)) * 100, 2), '% , loss :', loss.item())
return epoch_loss / len(iterator)
Testing
Here is the code to test our model, which uses the bleu measure.
def test_model(num_examples):
iterator = test_iter
model.load_state_dict(torch.load("./saved/transformer-100.pt"))
with torch.no_grad():
batch_bleu = []
for i, batch in enumerate(iterator):
src = batch.src
trg = batch.trg
output = model(src, trg[:, :-1])
total_bleu = []
for j in range(num_examples):
try:
src_words = idx_to_word(src[j], loader.source.vocab)
trg_words = idx_to_word(trg[j], loader.target.vocab)
output_words = output[j].max(dim=1)[1]
output_words = idx_to_word(output_words, loader.target.vocab)
print('source :', src_words)
print('target :', trg_words)
print('predicted :', output_words)
print()
bleu = get_bleu(hypotheses=output_words.split(), reference=trg_words.split())
total_bleu.append(bleu)
except:
pass
total_bleu = sum(total_bleu) / len(total_bleu)
print('BLEU SCORE = {}'.format(total_bleu))
batch_bleu.append(total_bleu)
batch_bleu = sum(batch_bleu) / len(batch_bleu)
print('TOTAL BLEU SCORE = {}'.format(batch_bleu))
Test Result
source : an oriental person in a red shirt and black pants crouching over a purse on concrete .
target : eine person orientalischen in einem roten shirt und schwarzer hose hockt über einer handtasche auf dem beton .
predicted : ein frau in in einen einem und ein und auf ein . einem .
BLEU SCORE = 19.018777246233505
source : a small boy wearing baseball holds a bat behind his head with a baseball mounted in front of him .
target : ein kleiner junge in holt mit einem schläger hinter seinem kopf in richtung eines vor ihm baseballs aus .
predicted : ein junge junge in einem und eine einem und einem und einem und einem . . . einem . .
source : two male curling players are on ice sweeping the path in front of rock , a small crowd watches .
target : zwei männliche sind auf dem eis und wischen den pfad vor dem stein , während eine kleine menschenmenge zusieht .
predicted : zwei männer männer in auf einem und ein und auf einem . während ein . . . .
source : woman wearing brown sandals and blue jeans , in a white shirt , holding a baby under a tall tree .
target : eine frau in braunen sandalen , blauen jeans und einem weißen shirt hält ein baby unter einem großen baum .
predicted : ein frau in einem hemd und die hemd und ein hemd und auf und einem . . . .
source : a young child wearing an orange life vest holding an oar paddling a blue kayak in a body of water .
target : ein kleines kind in einer orangefarbenen rettungsweste hält ein und paddelt in einem blauen kajak auf einem gewässer .
predicted : ein mann mädchen in einem roten hemd und auf und eine auf einem . einem . . . .
source : five people walking up a set of stairs led by a woman in a pink shirt and brown skirt .
target : fünf personen , von einer frau in einem pinken hemd und braunen rock , gehen eine treppe hoch .
predicted : drei gruppe in die und einem und einem , ein , während auf . . . . .
source : a man dressed in boots and a cowboy hat sits atop a horse that is jumping while spectators sit in the stands .
target : ein mann in stiefeln und einem cowboyhut sitzt auf einem springenden pferd während zuschauer auf den tribünen sitzen .
predicted : ein mann in einem und eine und auf einem mann und ein und einem . auf . . . .
source : a young girl with curly blond - hair and wearing a white top lies in the grass , holding a flower stem .
target : ein junges mädchen mit blonden haaren in einem weißen top liegt im gras und hält einen .
predicted : ein mann mädchen in einem und hemd und einem hemd und auf und eine auf . . . . .
source : a family is walking on the sidewalk through the snow while a man sits on the side with his paper cup .
target : eine familie geht auf dem gehsteig durch den schnee während am rand ein mann mit seinem sitzt .
predicted : ein frau in auf einem und ein und ein und und einem . auf . . . .
source : a child in a red coat waves a hand in the air while lying in snow beside a red plastic sled .
target : ein kind in einer roten jacke winkt mit einer hand während es neben einem im schnee liegt .
predicted : ein mann in einem blauen hemd und auf einem und ein und einem und . auf . . . .
source : four men , three of whom are wearing prayer caps , are sitting on a blue and olive green patterned mat .
target : vier männer , drei von ihnen mit , sitzen auf einer blau und gemusterten matte .
predicted : zwei männer in die einem und einem und die auf einem und ein , . . . . . .
Thanks for your reading, if you have any questions feel free to contact me, my email is longxhe@gmail.com.I’ll really appreciate it if you could star my Github project https://github.com/Say-Hello2y/transformer.
REFERENCES
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł. and Polosukhin, I., 2017. Attention is all you need. Advances in neural information processing systems, 30.
Zhang, A., Lipton, Z.C., Li, M. and Smola, A.J., 2021. Dive into deep learning. arXiv preprint arXiv:2106.11342.
lynn-evans, s., 2022. How to code The Transformer in Pytorch. [online] Medium. Available at: https://towardsdatascience.com/how-to-code-the-transformer-in-pytorch-24db27c8f9ec .
GitHub. 2022. GitHub - hyunwoongko/transformer: Implementation of “Attention Is All You Need” using pytorch. [online] Available at: https://github.com/hyunwoongko/transformer .